Tinkering with Metromile driving data in AWS Athena
Metromile is a car insurance company that has been a leader in the pay-as-you-go insurance marketplace. Their rates are calculated based on two components:
- a base rate composed of the rating for the vehicle type (think Porsche vs Toyota Camry) and the registered address (home address) of the vehicle
- a per-mile rate for a driver based on their driving history / available data
In order to calculate the per-mile billing, the company issues you an ODB-II adapter (more on ODB-II). When installed in the car, the ODB-II adapter tracks all sorts of data which can be fun to export from their service and analyze.
Enter Athena. Athena is a query service allowing users to write SQL-standard queries against flat files stored within S3 buckets. Athena doesn’t do anything any entry level programmer could do with basic data ingestion, transformation, etc… on their own. That said, in my opinion, it isn’t entirely meant for engineers so much as it is for business or analytics users.
Using the Athena is pretty simple. High level, Athena has databases and tables that point to external data. The setup consists of the following steps:
- Create an S3 bucket for your data
- Place your data within S3
- Use the Athena JDBC driver and a SQL client that supports JDBC drivers (or) use the AWS Console to create a database and table.
- Write and run queries using the JDBC client or Console to test, then save the queries as a named query.
- AWS Athena SDK users cannot directly access databases or tables, but they can invoke named queries and retrieve results. The results and metadata around a query’s execution are stored within another, automatically created S3 bucket in the same AWS account.
We’ll walk through most of these steps now…
Metromile Driving Data
I’ll use the AWS Console for table creation and use the default database “default” for this Metromile example. First off, let’s get our data. Obviously, you’ll need to be a Metromile customer and have your authentication information…
- Login to Metromile @ (https://www.metromile.com/[https://www.metromile.com/])
- Once logged in, select your profile icon in the upper right, then select “Account Settings”
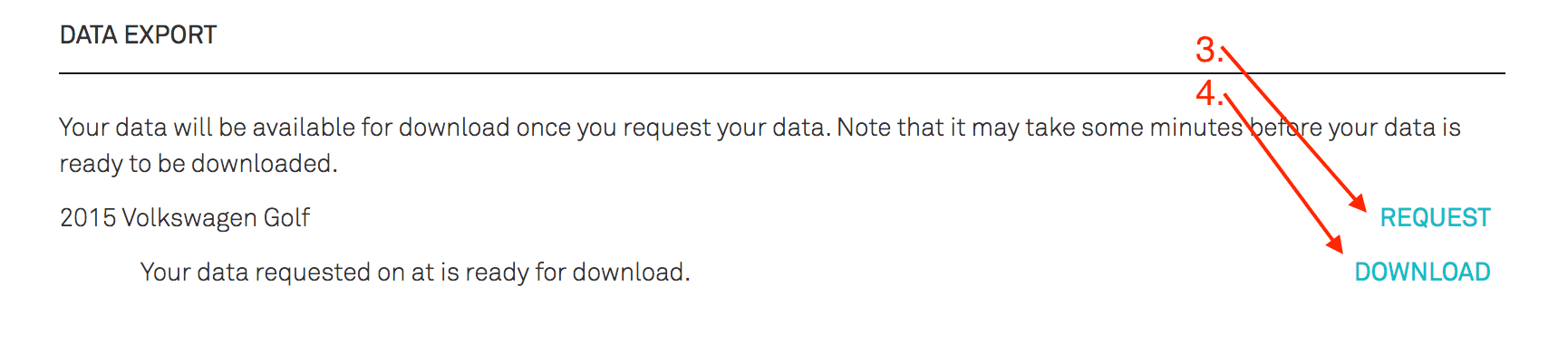
- Once on Account Settings, scroll to the bottom half of the page until you find the section “Data Export”

- Once in the Data Export section, select the “Request” button on the right-hand side of the window
- A “Download” link should appear in a few seconds (depend on their backend load, presumably). Click it and download your data!
S3, Athena Setup
Now that we’ve got the data, let’s get it into AWS S3 and query across it in Athena.
First off, we need to create our data storage – an S3 bucket.
- Create your bucket, in this case, “durbsblurps-metromile-data” –
aws s3api create-bucket --bucket durbsblurps-metromile - Explode the file downloaded from Metromile. In this case, the resulting files are stored in “Downloads/123456789 all_driving_data”. –
aws s3 cp Downloads/123456789\ all_driving_data/ s3://durbsblurps-metromile/athena-data --recursive. Take note of the target directory location within bucket ofathena-data.
Now let’s hop into the AWS Console for our Athena usage.
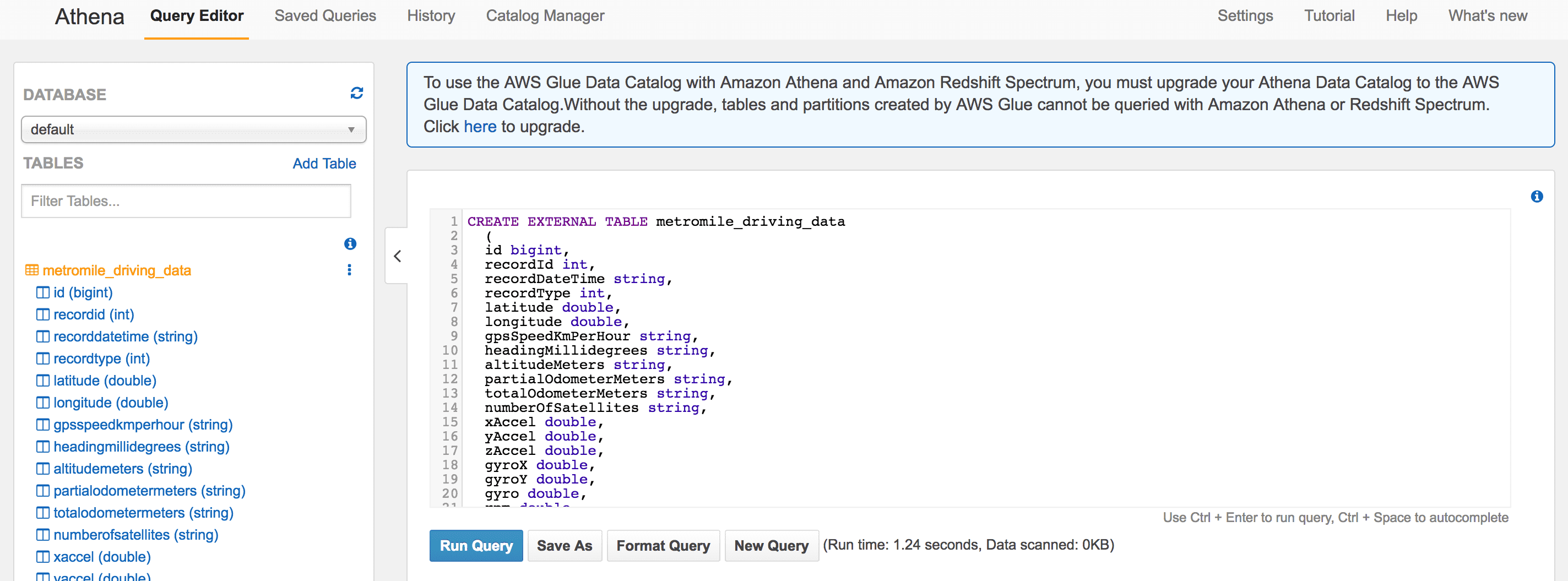
Once in the Console, go to the Athena service landing page. When you arrive on the landing page, the first element you’ll likely focus on is the query editor. The query editor can be used to query, obviously, and to create the external tables with the necessary configuration data for our S3-based data import.
Data can be in a variety of formats; Apache Web Logs (regex), CSV, TSV, Text with
custom delimiters, JSON, Parquet, and ORC. Our Metromile data dump is in CSV format. There
is a slew of arguably poorly documented options for each of these formats. For example,
the CSV importer supports skipping the header line, should it exist, for a CSV (TBLPROPERTIES property 'skip.header.line.count'='1').
To create our table representing our Metromile driving data, execute the following block in the query editor:
CREATE EXTERNAL TABLE metromile_driving_data
(
id bigint,
recordId int,
recordDateTime string,
recordType int,
latitude double,
longitude double,
gpsSpeedKmPerHour string,
headingMillidegrees string,
altitudeMeters string,
partialOdometerMeters string,
totalOdometerMeters string,
numberOfSatellites string,
xAccel double,
yAccel double,
zAccel double,
gyroX double,
gyroY double,
gyro double,
rpm double,
vehicleSpeedSensorKmPerHour int,
controlModuleVoltage string,
manifoldAirFlowGramsPerSecond double,
stringakeAirTemperatureCelcius string,
manifoldAbsolutePressureKilopascal string,
malfunctionIndicatorLampOnDistanceKm string,
malfunctionIndicatorLampClearDistanceKm string,
firmwareVersion string,
softwareVersion string,
voltagePoweringDeviceBeforeIdle string,
voltagePoweringDevice string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://durbsblurps-metromile/athena-data'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1')
Once the Query is finished, your new table should display on the left. Selecting it shows the particular properties that map to the underlying data, the CSV flat files, stored in the S3 bucket we created earlier.
Athena Querying
I didn’t spend a whole lot of time working out queries against the Metromile data. I did, however, write up a quick query for pulling back which dates my vehicle was at a DIY/builder collective NIMBY in Oakland.
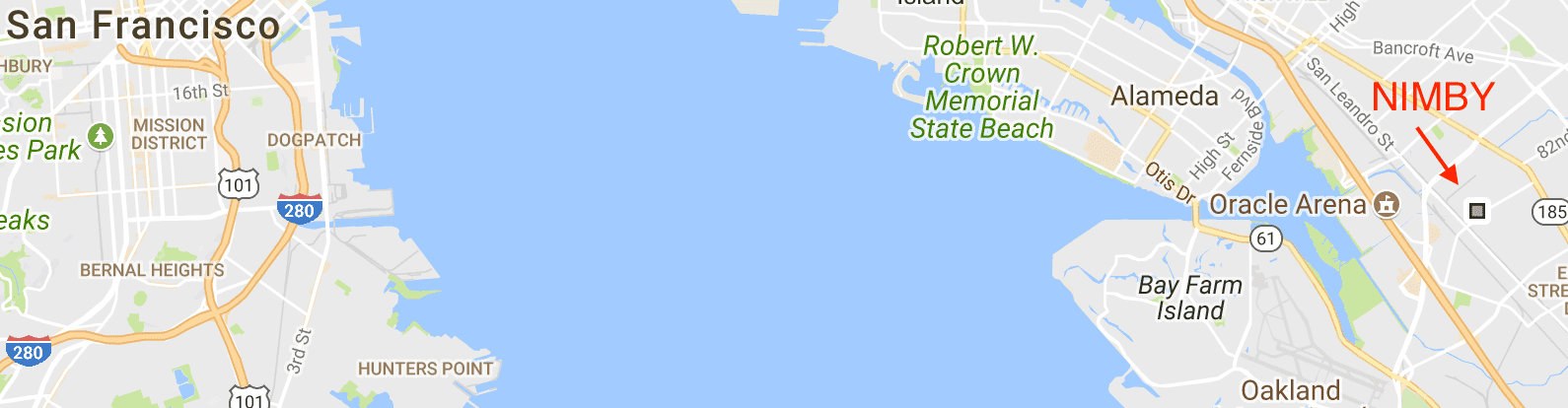
Using Google Maps I backed into a crude query of a lat/long “box” around NIMBY,
nearby streets for parking, etc… and came up with the following. Metromile supplies
its recorddatetime with timezone identifiers, which Athena does not like. Thus, the
property is a string, and transformations must be done in-line. You could run sed
or another tool across the dataset prior to insertion to the S3 bucket, but I chose this
approach for example’s sake.
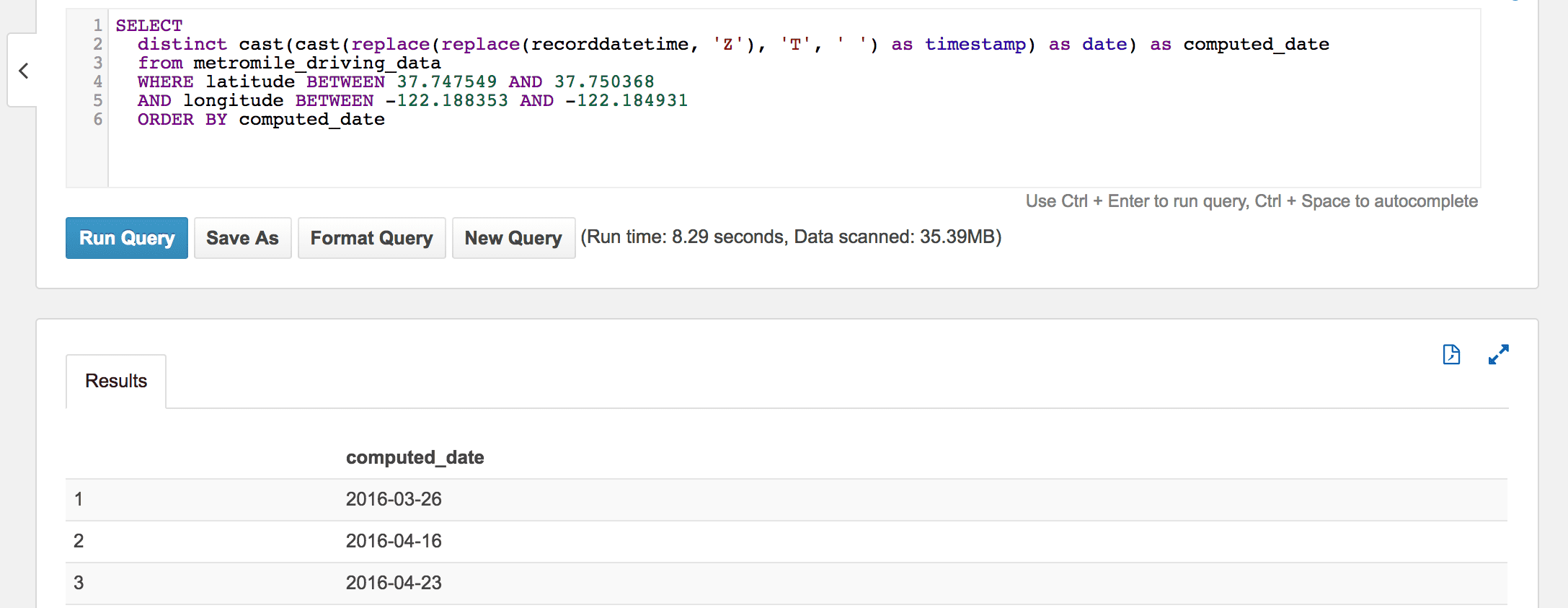
SELECT
distinct cast(cast(replace(replace(recorddatetime, 'Z'), 'T', ' ') as timestamp) as date) as computed_date
from metromile_driving_data
WHERE latitude BETWEEN 37.747549 AND 37.750368
AND longitude BETWEEN -122.188353 AND -122.184931
ORDER BY computed_date
Executing the query gives me the dates my car reported its location within the prescribed bounds. Every query, its results, and metadata around how what was queried, how long it took, etc… is stored and retrievable via the queries ID, which is auto-generated.
Execution of the query is tracked in the aforementioned S3 bucket with the query, metadata, and results returned. Simple execution of the query does not create a “named query”, which is required for users of the AWS Athena SDK.
Queries reflect data updated, added, and removed from the source S3 buckets in real time and require no engineering effort. While I’m not sure I would use Athena day-to-day, for near zero cost flat file ETL processing for business users it’s pretty cool.